前言
在工作中发现关于性能优化相关的工作,大部分人都较少涉猎,也缺少相关的经验,所以把我的经验记录下来,抛砖引玉。
需求
性能需求
在一个系统运行的过程中,遇到性能上的需求无法满足是非常常见的。例如:
- 一个 HTTP 服务器的某个请求响应时间过长。
- 一个消息队列同时可以发送、储存的消息数量不足。
- 一个脚本的执行时间过长。
高性能往往可以具体拆解为低延迟和高吞吐量。只不过对于每个系统来说,低延迟和高吞吐量的衡量标准有所不同。在开始进行性能优化之前,我们先要确定需要优化的是什么。
性能优化思路
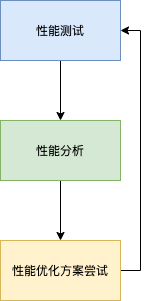
对于大部分的系统来说,性能优化都可以拆解为几个通用步骤:
- 性能测量。针对需要优化的系统,确认一个可重复、可测量的指标作为性能的衡量标准。优化目标就是将该指标增大或者减小。
- 性能分析。针对我们需要优化的系统,分析系统完成特定任务时进行过的操作,以及各操作所消耗的时间、资源。
- 尝试优化方案。根据上一步得到的信息,进行理论上的分析,找到可以进行优化的方案,并尝试实施对应方案。
下面我抛出3个常见的优化场景,并且举几个例子说明怎样将这个优化思路落地:
- 低延迟优化:有一个 Django 服务的某个请求响应时间过长,需要 3 秒左右返回。
- 高吞吐量优化:有一个消息队列同时可以发送的消息数为 5000 条/秒,需要能达到 50000 条/秒。
- 低延迟优化:有一个 python 脚本的执行时间过长,需要 20 分钟完成。
性能的衡量标准
对于低延迟的系统,衡量标准就是时间,在完成某个特定任务的情况下,衡量每个任务的完成时间。在衡量时需要尽量保证可重复、可测量。
可重复:对于许多系统的优化任务来说,不符合需求的性能场景可能无法稳定复现,例如响应时间过长的问题不是每个请求都会出现。那么我们的第一件事是找到复现这个响应时间过长的情况。因为如果响应时间过长的问题不是稳定出现的话,做出来的性能分析也不是针对出问题的场景,那我们就没办法进一步做性能分析了。如果系统的表现不稳定的话,可以尝试将衡量的组件范围减少,当每次执行任务的时候涉及的组件、模块、功能越少,则表现也就相对会越稳定。
可测量:对于系统优化的任务,一定要有一个可测量的指标用于衡量性能。如果不能测量,只是靠感觉的话,那优化任务就没有一个尽头了。所以一定要有一个可测量的指标,用于衡量优化的效果。
性能的分析方法
性能的分析主要目的是:
- 对于延迟类的性能需求,找到时间花在哪了。
- 对于吞吐量的性能需求,找到当吞吐量达到最大值时,同时达到瓶颈的资源。这个瓶颈可能是网络带宽、磁盘 IO、端口数等等。
系统延迟的分析
当我们要分析时间花在哪的时候,首先尽量把任务隔离成单线程/单进程任务,对每个线性处理流程分析完毕后,再进行多线程/多进程的分析,这样可以隔离分析的复杂度。
线性系统的Profiling
要找时间花在哪时,一定会用到 Profile。Profile 的意思是测量,测量一段代码的时间使用/内存使用/IO使用情况。对于每个系统,Profile 的方法会有所区别。这里拿代码的执行时间使用的 Profile 做例子。
对于一段 Python 代码,常用的工具可以用 cProfile,cProfile 内置在 Python 的标准库中,可以将每个方法调用所消耗的时间记录下来:
$ python3 -m cProfile -s cumtime test_smtp.py | less
{}
36884 function calls (35925 primitive calls) in 0.438 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
52/1 0.003 0.000 0.438 0.438 {built-in method builtins.exec}
1 0.000 0.000 0.438 0.438 test_smtp.py:1(<module>)
7 0.000 0.000 0.237 0.034 smtplib.py:369(getreply)
12 0.000 0.000 0.237 0.020 {method 'readline' of '_io.BufferedReader' objects}
7 0.000 0.000 0.237 0.034 socket.py:572(readinto)
7 0.000 0.000 0.237 0.034 ssl.py:1001(recv_into)
7 0.000 0.000 0.237 0.034 ssl.py:866(read)
上面的这个信息也可以导出一个文件后,通过第三方的画图工具,画成一个火焰图,火焰图可以更直观地对每个函数之间的调用关系和耗时进行下钻分析。
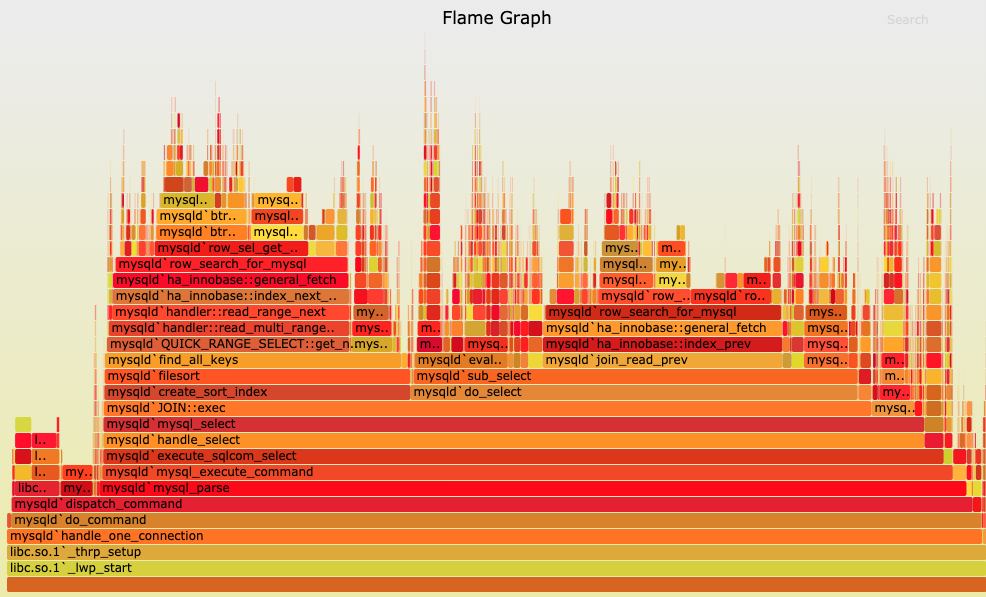
同理,对于 java、c++ 可以用 VTune 之类的工具,在执行代码的同时记录每个函数的执行时间。在 Google 上搜索 语言 + profile 一般就可以找到适合的分析器了
在看到了每个函数的执行时间之后,我们分析可优化的点就可以按照几个思路来推进:
- 分析耗时最长的部分。由于我们能看到每个部分的耗时,从耗时最长的部分一层层往下找,看是否有可以优化的地方。
- 分析耗时是否合理。分析耗时的合理性时,要从两方面分析,
- 整体执行的代码内容是否合理,是否调用了不需要调用的代码。例如在一个循环内不断调用 SQL 查询语句,是一个常见的不该出现的情况,在使用 ORM 时,如果没注意联合查询的使用,会导致调用大量的 SQL 从而拖慢整体速度。或者在一个循环内不断出现 fetch_many 的数据库调用,可能是查询时拉取了文本或者 glob 字段的内容,导致每个批次数据拉取速度比较慢。
- 代码内每个步骤的时间是否合理。有一部分操作可能在代码的 profile 上看不出细节,例如将一个文本类型的时间转为时间对象,在格式不确定的情况下需要穷举可能匹配的格式(YYYY-DD-MM 或者 YYYY-MM-DD),会耗时很长 ~200ms。但是在格式确定的情况下,通过正则或者原生的 strptime 这类方法,可以利用正则状态机的方法,实现 O(1) 的转换时间,约 ~1ms。或者例如一个看起来简单的 sql 的执行可能花了10秒的时间,但是从代码的 profile 上看不出为什么花了10秒的时间。此时就可以用 sql 的 profile 分析器去查看 sql 执行的每个步骤所花的时间。
- 代码执行的逻辑是否可以优化。例如 O(n^2) 的代码是否可以通过缓存简化为 O(n)。
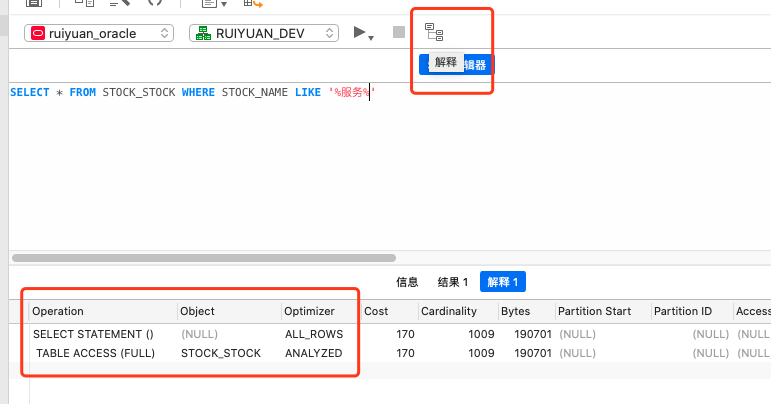
对于 SQL 语句的性能分析,我们可以使用 SQL 分析器,也叫 sql 解释器,在 Google 上搜索 具体的数据库 + “sql analyzer” 一般就可以找到适合的工具了。
SQL 分析器可以把 sql 语句的执行过程拆解为在数据库端的索引查询、原文提取等步骤,利用这个信息,我们可以进一步分析数据库端,整体时间消耗在了哪,例如是不是有缺少索引导致的全表扫描,或者缺少联合索引导致的大数据量的 join。
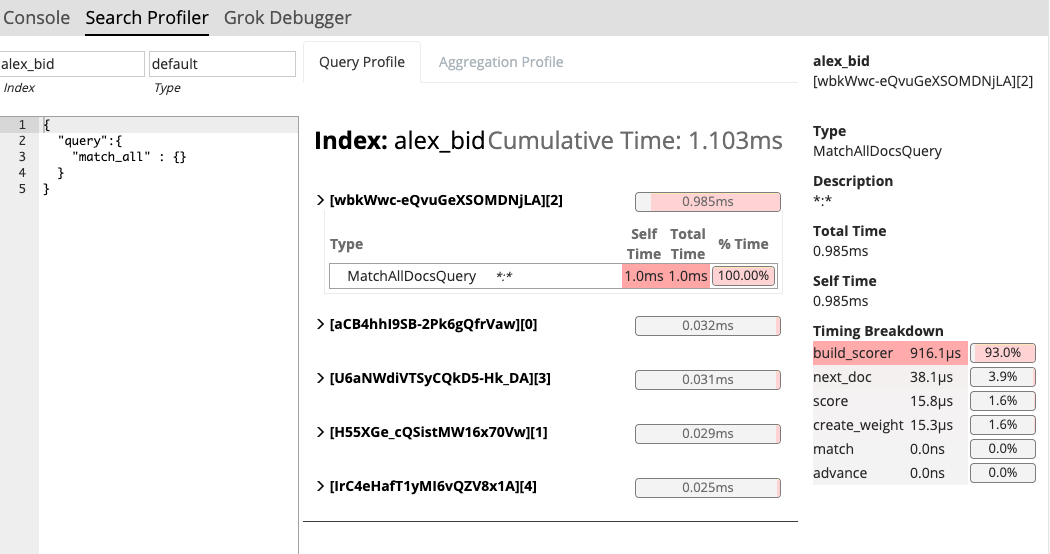
同理,对于 Elasticsearch 等 NoSQL 数据库,也可以利用 Kibana 中的 Profile 工具,查看 Elasticsearch 搜索时底层的耗时,从而判断可以进行优化的点。
对于一些较复杂的问题,可能会涉及到更低层的 profiling,例如我们发现某个文件的读写花的时间比预期长,那我们可以使用 strace 对每个 system call 的耗时进行 profile,例如 open, fstat 等。或者我们发现某个 tcp 连接的耗时较长,那我们可以使用 tcpdump 对 tcp 的三次握手包进行抓包,通过在不同节点进行抓包,可以找到网络请求慢的节点,从而进一步分析。
Django的在线性能分析
针对目前公司内使用的 Django 框架,可以使用 silk 库进行性能分析。由于性能分析需要测量并记录大量数据,会极大影响整体的性能,我们需要能在生产环境或者测试环境便捷地开关性能分析。此时可以对 silk 的接入做一些改造,通过环境变量控制是否打开性能分析。
settings.py
ENABLE_SILK = os.environ.get("ENABLE_SILK", "False").lower() == "true"
if ENABLE_SILK:
INSTALLED_APPS.append("silk")
MIDDLEWARE.append('silk.middleware.SilkyMiddleware')
# 启用cProfiler
SILKY_PYTHON_PROFILER = True
# 查看SILK本身带来的延迟
SILKY_META = True
# 最多储存 1000 条数据
SILKY_MAX_RECORDED_REQUESTS = 10**3
SILKY_MAX_RECORDED_REQUESTS_CHECK_PERCENT = 10
# 动态profile
SILKY_DYNAMIC_PROFILING = []
# eg. 通过配置修改需要profile哪些代码
# export ENABLE_SILK=true
# export SILK_MODULE=users.views
# export SILK_FUNCTION=UserAccountLogin.post
silk_module = os.environ.get("SILK_MODULE")
silk_function = os.environ.get("SILK_FUNCTION")
if silk_module is not None and silk_function is not None:
SILKY_DYNAMIC_PROFILING.append({
'module': silk_module,
'function': silk_function
})
通过环境变量,我们可以通过控制 ENABLE_SILK 来开启或关闭 silk 是否加入 middleware 中。从而可以看到整体系统的请求延迟统计。
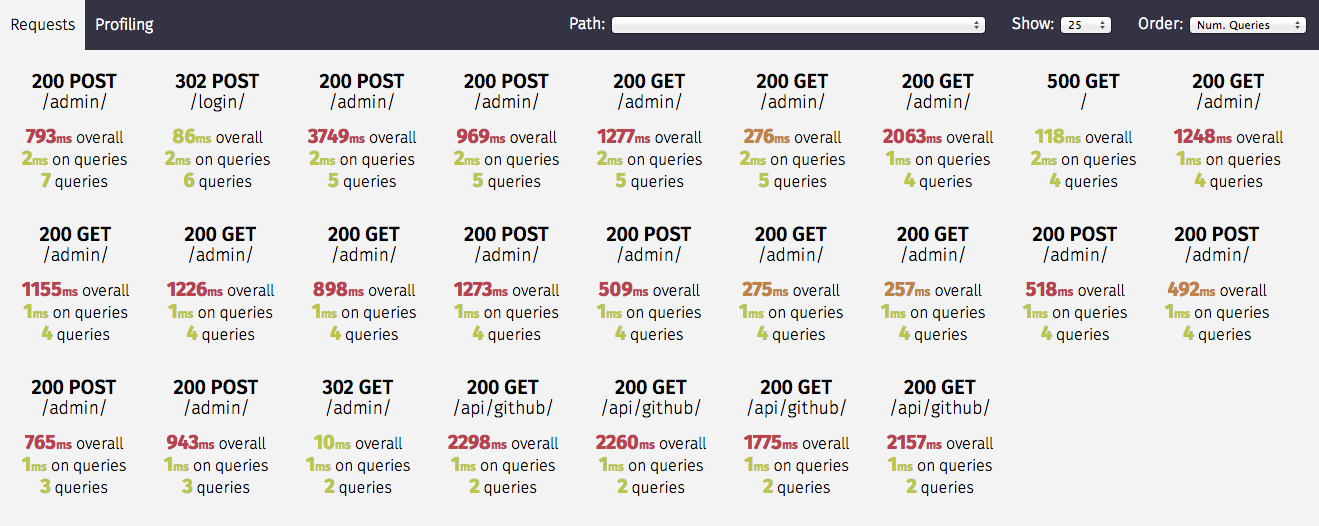
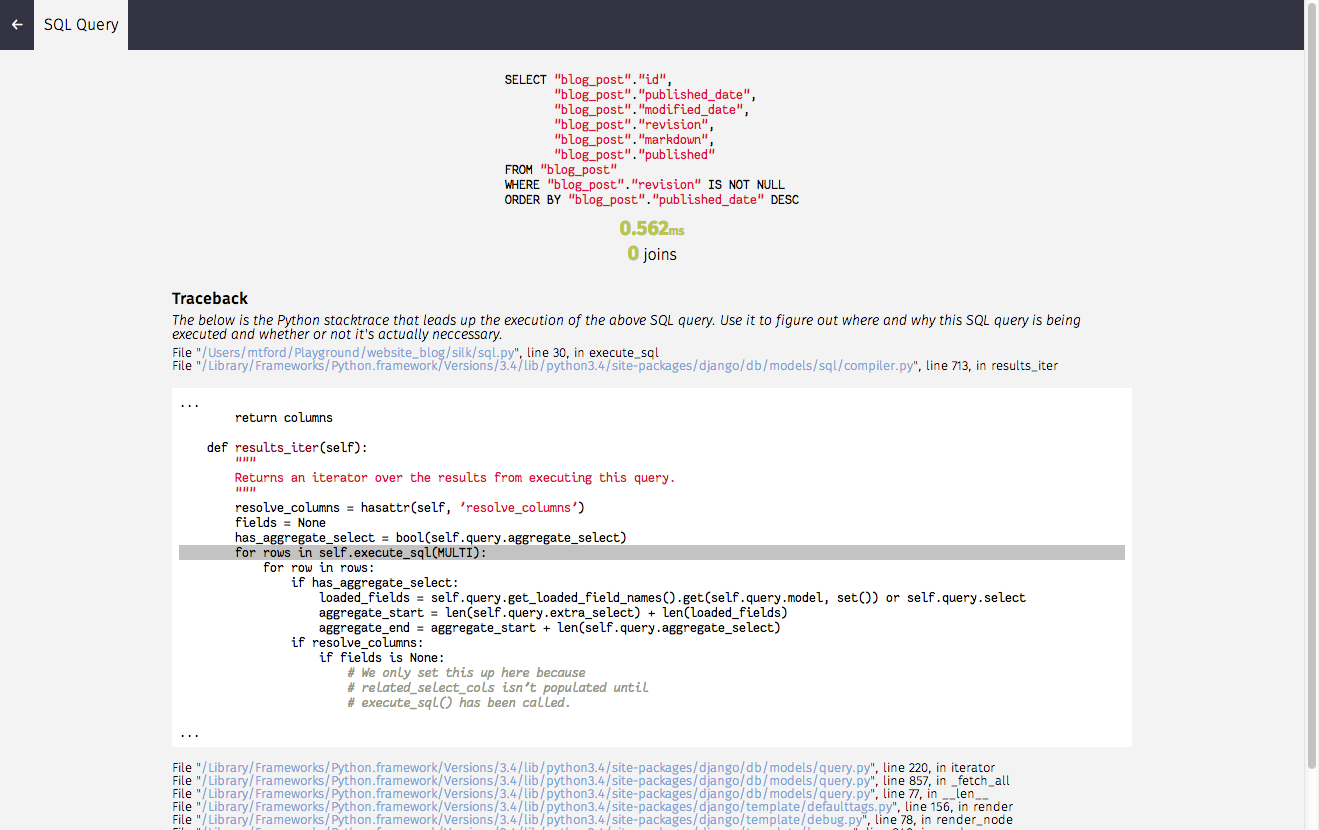
同时,我们也可以通过 SILK_MODULE 和 SILK_FUNCTION 来使用 SILKY_DYNAMIC_PROFILING 的功能,动态地配置 silk 对某个类的某个函数进行 profile。看到每个请求具体在每一行代码的耗时,以及其中调用过的 SQL 和对应 SQL 的耗时。

系统吞吐量的分析
对于系统吞吐量的性能分析会相对比较复杂,一个系统的吞吐量瓶颈来源一般是系统中某个节点的资源瓶颈,例如 CPU、内存、磁盘、网络、文件句柄、端口数、线程池等等。这个时候我一般会把整个系统拆分为可以独立测试的子系统,例如 mock 一个子系统的输入,通过压测的方式判断这个子系统的吞吐量上限,从而判断在实际环境中,可能达到上限的资源使用量是多少。
例如一个常见的后端系统中,可能会涉及到 MySQL、ES、后端的HTTP服务器、负载均衡。此时对每个组件做压力测试后,我们可以了解到
- MySQL 常见的瓶颈为 CPU、连接数、内存大小
- ES 常见的瓶颈为网络 IO,磁盘IO延迟,数据解析的节点的 CPU
- 后端的 HTTP 服务器常见的瓶颈是 CPU、内存
- 负载均衡的瓶颈是端口数、CPU、网络带宽
那么此时我们对整个系统就可以建立一个监控面板,在压测的同时观察哪个子系统的资源先达到瓶颈,再针对性的提出优化方案,例如扩容对应子系统的资源。
常见系统性能优化方案
缓存
业界常说 90% 的性能优化都是在加缓存,确实有许多问题是可以通过空间换时间,对代码关键路径上静态的信息做缓存实现,同时整个系统中对于大数据流的关键路径,也是可以尝试用缓存实现优化。
同时一部分数据从磁盘缓存到内存里,或者从远程机器缓存到本地机器,也是一个常见的缓存思路。
优化数据库查询
另外一个常见的优化方向是数据库查询。目前大部分的业务逻辑还是使用 SQL 数据库来完成的,而数据库的复杂查询往往也是耗时较多的一个来源。例如查询时对涉及的字段加索引,或者优化查询语句,只提取需要的字段,避免 select * 语句。
数据库查询的优化在进行时,也是可以遵循上述的先 profile 分析,再优化的方式,避免瞎猜测原因。
性能的分析工具以及阅读材料
-
cProfile - Python profile https://docs.python.org/3.6/library/profile.html Python 内置的 profiler
-
因特尔 Vtune https://software.intel.com/zh-cn/vtune 支持几乎所有主流编程语言 C / C++ / C# / Fortran / Java / Python / Go / 汇编
-
火焰图 Flame graph http://www.brendangregg.com/flamegraphs.html