AI School
在今年年初我收到一封邮件,是微软 2022 年 AI School 的报名邀请。AI School 是微软亚洲研究院主持的内部 AI 课程系列,今年是开办的第四年。今年的课程方向有 3 个,音乐、股票和游戏。由于过去多年在金融科技行业的工作经验,我选择了股票方向,同时旁听了一下其他两个方向的课。
AI + Stock 方向主要是围绕着 Qlib 这个开源项目展开的。Qlib (https://arxiv.org/pdf/2009.11189.pdf) 是一个量化研究的工具框架,它对我帮助最大的一个地方在于,它提供了完整的量化交易的生命周期的样例,包括数据采集、特征工程、模型开发、因子分析、模拟回测、模型表现分析各个阶段。同时这些样例组合起来还能提供一个不错的基础版的量化交易策略。
在大学刚毕业时,我也曾经尝试用神经网络模型建模预测股价,但是并不成功,原因是当时模型无法收敛,模型最终就拿昨天的收盘价作为第二日的收盘价预测值。当时我得出的结论是股价变化是不可预测的,就像 EMH (有效市场假说) 说的,市场是有效的,过去的信息无法预测未来。所以当我发现 Qlib 居然能收敛时,我第一反应就是要去对比研究为什么我的模型无法收敛。最后发现,其实特征工程是很关键的,使用无量纲的特征会使得特征的规律更加稳定,模型更容易学习到规律,同时预测标签的选择也很重要。
这篇博客会记录一下我学习到的一些有意思的技术和量化方面的经验,下一篇博客我会再详细说一下基于 Qlib 做的众包金融数据的项目。
Qlib在量化研究的各个阶段
数据采集
Qlib 自带的 A 股数据集主要是由两部分组成:
- 量价数据采集自 Yahoo Finance 的日度价格数据。
- 指数成分股数据采集自中证指数官网公告的附件。
量价数据采集下来后,会对量价数据进行一次归一化。归一化就是将所有股票的价格设置为在第一天为 1,后续每天的价格变化则由后复权因子乘以前一天的价格计算。这样一来分红、除权等事件对投资的影响也可以被正常处理。其中比较容易出错的一点在于成交量,当进行归一化后,成交量也需要换算,从而保证总成交额不变。
最后 Qlib 会将所有的数据导出为 numpy 格式的 array,每个股票的每个 feature 一个文件,后续使用时通过 numpy 直接加载。
- features
- sh000300
- adjclose.day.bin
- factor.day.bin
- high.day.bin
- low.day.bin
- open.day.bin
- close.day.bin
- volume.day.bin
- amount.day.bin
- sh000905
- ...
这个方案其实很巧妙,一来利用了操作系统里的文件内存缓存,不需要额外实现缓存机制也可以在第二次加载数据时快很多,二来使用成熟的 numpy array 进行序列化和反序列化,实现方法很简单,但是压缩率和性能都比使用 sql 数据库更好。
特征工程
Qlib 是通过 Data Handler 概念来封装特征工程的。
原始的量价数据在采集储存完之后,会通过 Data Handler 进行加载。Data Handler 可以通过传入多个 processor 的方式定义对数据的处理方法。在默认的 baseline 中提供并使用了两个 Data Handler:
- Alpha158:其实是一个经过筛选的技术指标特征集,里面提供了 158 个不同时间窗口,基于不同统计方法提取出来的技术指标:
- 主要是通过股票的过去量价数据,计算出 158 个技术指标,每个股票每天是一个训练集的一条样本,158 个技术指标是后续模型的输入,而预测的标签则是这个个股第二天相对于大盘的涨跌幅。
- 因子包括简单的 5 日、10 日、20 日收盘价时间序列的 std 标准差,还有稍微复杂一些的 RSI 中的 SUMD 因子,Alpha 158 涉及到的技术指标因子跟现有的技术分析库比起来还是少了很多的。
- Alpha360:相比 Alpha 360 这个更简单,它用过去60日的所有量价数据作为特征。唯一的处理就是去量纲化。预测的标签还是这个个股第二天相对于大盘的涨跌幅。
特征工程这里我认为有几个关键点:
- 特征的去量纲化。去量纲化的方法很简单,就是用类似
feature(close price) = next day close price / today close price的方法,使得股价的绝对值高低对模型没有影响。由于神经网络的激活函数的特性,归一化的特征会更容易训练和收敛。
- 训练标签的去量纲化。和特征的去量纲化方法一样。
- Alpha 158 并没有直接使用信号作为因子,而是将计算中的元素作为独立的因子,例如
MACD = 12日 EMA − 26日 EMA拆分为12日 EMA和26日 EMA各自作为独立的因子,让模型去学习因子之间的关联性。 - 使用 ZScoreNorm 处理预测标签,用每个股票的第二日涨跌幅与第二日涨跌幅的平均值相比,得到每个股票相对于大盘的涨跌幅。这个也简化了整个量化的训练目标,从训练学习股价的绝对变化,变成了训练学习股票之间好坏的目标
而这两个特征工程的主要区别在于,Alpha158 的特征异质化较强,比较像 Kaggle 上工业界的数据集,更适合 GBDT 之类的决策树模型训练。而 Alpha360 的特征同质化较强,比较像文本、图像的数据集,更适合神经网络模型的训练。
模型开发
Qlib 上训练的模型基本是围绕着一个任务:预测股票的第二日的相对均值的涨跌幅,来进行建模和训练的。模型的输入就是特征工程中输出的无量纲特征,每个股票每天的数据是一个 sample,而训练的标签就是这个股票第二日买入第三日卖出的差价。
Qlib 已经实现了多个常见的模型例如 GBDT,MLP,GRU 等,同时复现了很多 Paper 中的经典模型,使得开发一个新模型的难度也大幅降低。同时 Qlib 上也跑了多个模型的回测,如果开发了一个新的模型,也可以在同样的时间参数下跑回测,看看在对应的条件下,表现有什么区别,例如:
| Model Name | Dataset | Annualized Return | Information Ratio | Max Drawdown |
|---|---|---|---|---|
| MLP | Alpha158 | 0.0895±0.02 | 1.1408±0.23 | -0.1103±0.02 |
| LightGBM(Guolin Ke, et al.) | Alpha158 | 0.0901±0.00 | 1.0164±0.00 | -0.1038±0.00 |
| DoubleEnsemble(Chuheng Zhang, et al.) | Alpha158 | 0.1158±0.01 | 1.3432±0.11 | -0.0920±0.01 |
值得一提的是,这个数据并不代表这个模型的最好的效果,因为在 Qlib 复现研报或者 Paper 的时候,很多超参数是依照原 Paper 设定的,但是原 Paper 中发布模型时,可能会用到不同的数据集和特征工程,所以照搬来的超参数并不能代表模型能达到的最佳效果,但是可以提供一个大概的参考值。例如 DoubleEnsemble 中模型的训练 epoch 是写死的 100,但是如果能使用 Early Stopping 来防止过拟合,效果可以更好。
模拟回测
Qlib 中的回测框架实现包括两个部分,一个是交易策略,一个是交易所模拟成交。
交易策略
默认样例的交易策略是 TopKDropout,根据模型预测的分数,选择分数最高的 K 只股票作为下一日的等权持仓。同时为了控制换手率,增加一个调仓的限制,即每日最多调仓 N 只股票,如果需要调仓的股票数量大于 N,则选取待调入股票中分数最大的 N 只买入,待调出股票中分数最低的 N 只调出。
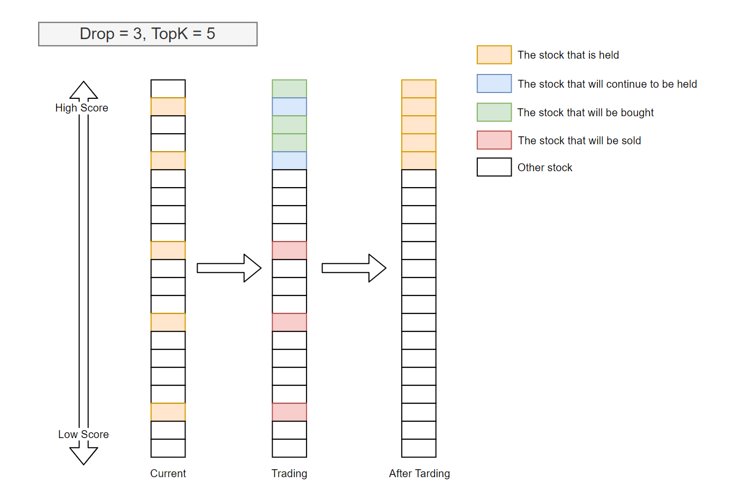
这里我认为默认的 TopKDropout 的交易策略其实有很大的调优空间:
- TopK 的选择。
- 较小的 TopK 意味着选取的持仓更集中,更容易利用模型预测分数较高的股票集,但是较集中的持仓也意味着超额收益更不平滑。
- 如果 K 值相对于整体股票池的数量过小,则 TopK 的盈利能力可能很不稳定,回测的信息比率会比较低。我在沪深300中,选取 topK = 50 的参数,那么在中证 500 中,就需要选取 topK = 100 才能有类似的信息比率,如果选取 topK = 5 收益可能会很差。这是由于我们训练的 loss 函数是针对整体股票池来设定的,所以当我们只取很少一部分股票时,loss 值可能会大幅偏离平均的 loss 值。
- K 值较大的时候,会使得持仓中包含许多超额收益较低的股票,拉低整体的超额收益。
- 对于不同的股票池和模型,K 值是一个需要调优的超参数。
- Dropout 数量 N 的选择。
- 较大的 N 可以提供最快的市场反应速度,当模型的预测值发生变化后,可以最快反映在持仓中。
- 但是较大的 N 也会使市场噪声更容易引起股票调仓,引入不必要的交易费率。
- 较小的 N 会强制降低换手率,减少交易费率,但是也可能由于换手不及时导致一部分亏损。
- 如果当模型预测足够好时,可以在模型层面使得预测的分数较稳定,减少换手率。这是模型训练的一个优化方向,一部分模型可以修改预测的 label 使得预测结果更稳定。
- 对于不同的股票池,不同的 TopK 选择,不同的模型,N 值的选择都是一个需要调优的超参数。
- 交易策略的训练。
- 交易策略在整体量化中占有很关键的位置,直接决定了最终的盈利能力。对于 TopKDropout 的交易策略来说,TopK 和 DropoutN 的超参选择对最终信息比率的影响非常大,那么是不是可以将交易策略也用机器学习的模型来训练呢?
- 对于交易问题来说,可以利用的信息有:
- 模型对所有股票的预测值
- 过去 N 天的预测 IC 和 IR 值
- 验证集上的平均 IC 和平均 IR 值
- 当前的股票仓位
- 我们最终输出的是调仓的决策。这其实可以用强化学习来建模训练,reward 就是第二天扣费之后的超额收益。这样一来我们就可以自动化地根据不同的模型来获得最佳的交易策略。
- 如果能最大程度优化模型能产生的超额收益,才能尽可能地反应量化模型的效果。例如我曾经测试后发现一些模型在 DropoutN = TopK 的时候效果最好,但是一些模型则是 DropoutN = TopK * 30% 的时候效果最好,如果要比较模型的话,就不能用固定的交易策略,否则就不公平。
交易所模拟
交易所模拟则是比较直接的 event driven 模型:在每一日结束时,交易策略生成目标持仓后,交易所根据配置的价格模拟交易的进行,同时更新持仓情况。
不过这里设计上有一点缺陷,就是无法设置多个交易所参数,每个参数只能设置一个值,例如:
- 科创板每笔申报最少 200 股,主板每笔申报 100 股。
- 科创板创业板涨跌停幅度为 20%,主板为 10%。
如果我们交易的股票池中有多个交易所的资产时,就不好配置交易所的涨跌停限制和单手股数的限制,回测的数据可能会失真。
模型表现分析
在分析模型时,Qlib 提供了多种指标和可视化的方法,我觉得最有用的是两个:
1. 回测的收益分析
Qlib 提供了 analysis_position.report_graph() 工具绘制收益率曲线,并统计收益的统计数值:
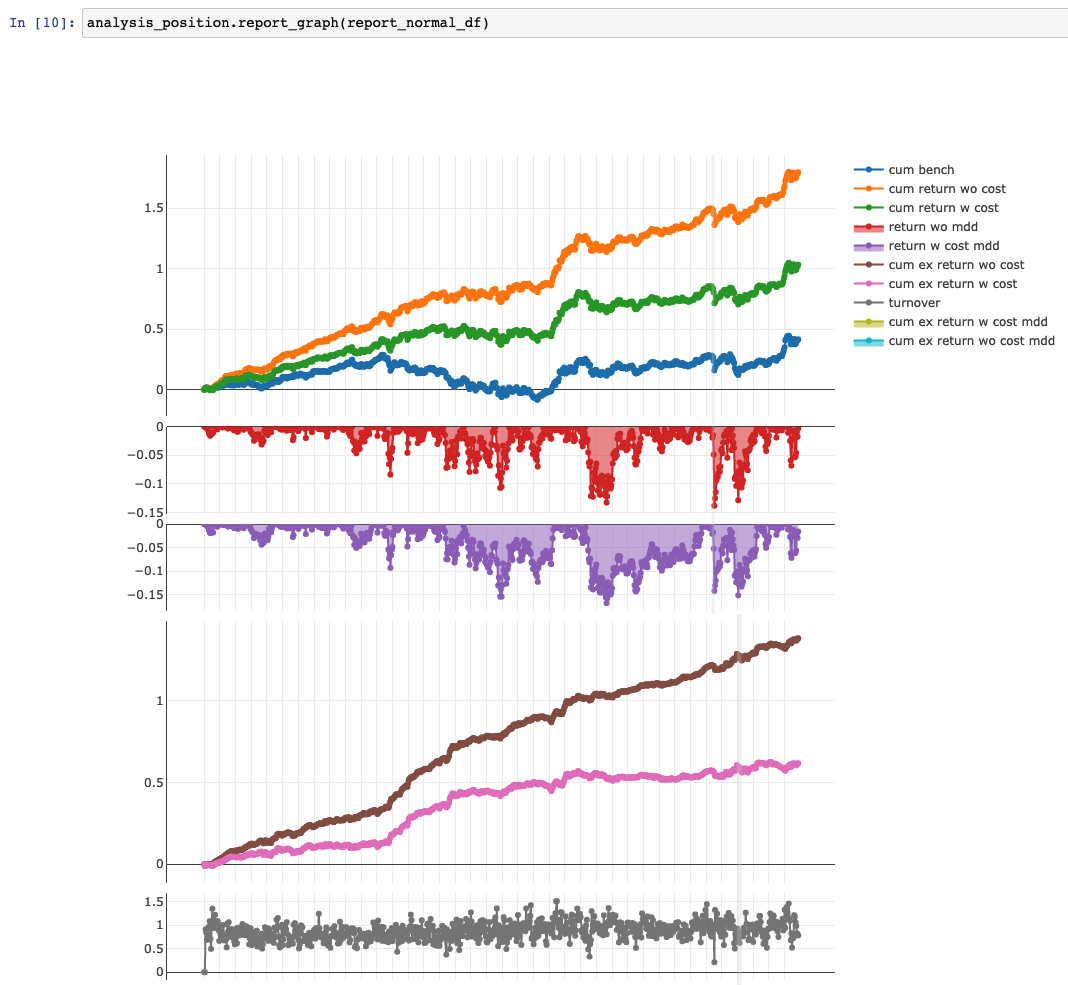
'The following are analysis results of the excess return without cost.'
risk
mean(每日收益均值) 0.001925
std(每日收益标准差) 0.006728
annualized_return(年化收益) 0.458228
information_ratio(信息比率) 4.414830
max_drawdown(最大回撤) -0.050502
'The following are analysis results of the excess return with cost.'
risk
mean(每日收益均值) 0.000958
std(每日收益标准差) 0.006740
annualized_return(年化收益) 0.228030
information_ratio(信息比率) 2.193174
max_drawdown(最大回撤) -0.079578
回测的收益提供了包含费率和不包含费率的结果。不包含交易费率的结果反映了模型预测的准确性,而包含交易费率的结果则反映了交易策略对模型的利用程度,以及是否能在实盘中盈利。
2. 回测期间股票分组的回报
Qlib 同时提供 analysis_model.model_performance_graph() 方法来绘制模型的分组收益曲线,即如果把股票池的股票分成 N 组,每组组成一个模拟组合,在回测期间他们的收益曲线画在整个图中。
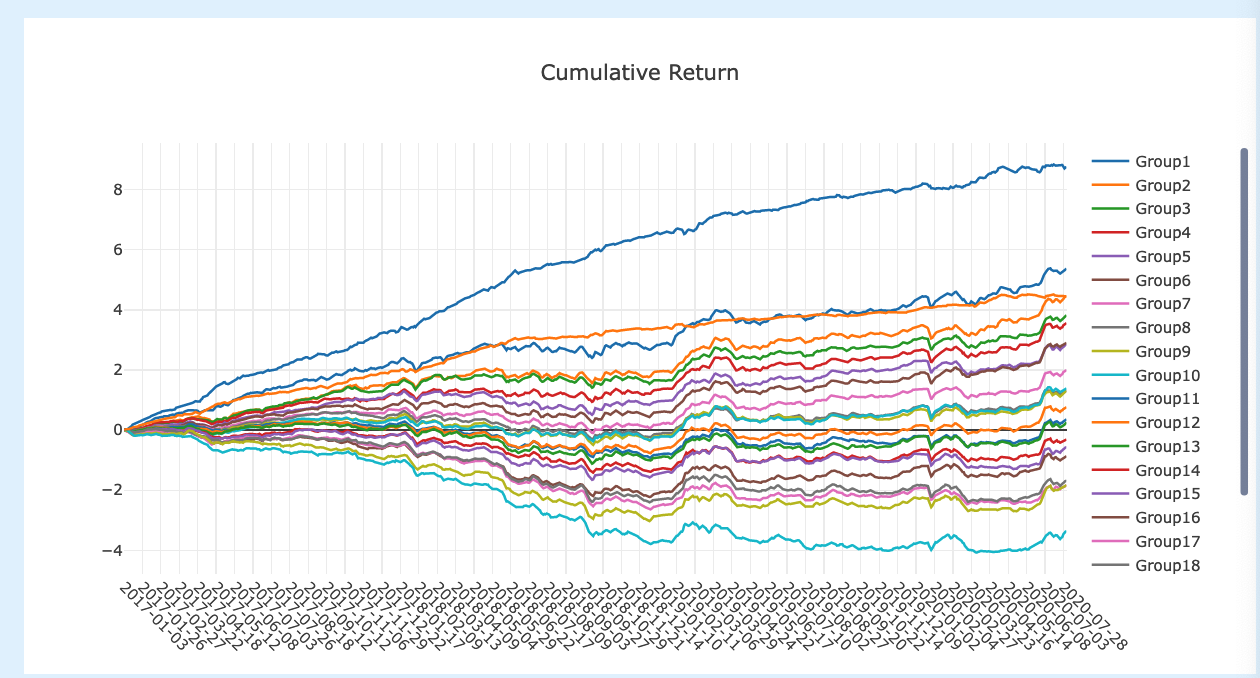
这个图可以帮助我们分析模型预测的特点。
- 例如我们可能会发现 N = 20 时,Group 1 和 Group 2 的曲线很相近,那么说明模型在 top 5% 和 top 10% 股票的预测上并不是很有区分度,也许在交易策略上最好将 top 10% 的股票都囊括进来。
- 或者我们可能会发现 Group 1 的股票表现大幅优于 Group 2,甚至出现年化 2000% 的收益,但别高兴的太早,可能是模型在 Top 5% 的股票中出现大量的一字涨停板,但是回测时不会将这些股票包含进去。
- 我也曾利用这个工具找到了一些股票数据中的异常值,因为异常的价格变化会导致曲线过于陡峭或者出现断层。
量化经验
机器学习量化赚的是什么钱
Qlib在回测中的表现大大刷新了我对市场有效假说的认知。我在过去认为市场短时间内可能会出现一些由于交易量冲击导致的套利机会,但是应该不存在基于量价信息能稳定盈利的手段,否则应该有大量玩家挤入这个市场,从而降低盈利空间直到不足以覆盖交易成本为止。但是 Qlib 的回测超额是远远超过券商佣金的,所以我猜测:
- 从机器学习学到的交易信号来看,有不少基于支撑位、阻力位、以及过去价格波动率的信号。看起来它赚的钱有很大一部分来源于投资者的短期情绪极值,例如阻力线附近的超跌反弹,或者是突破阻力线之后的趋势启动点。这个交易思路是有一定行为金融学理论的支撑的。
- 这类策略已经有不少人在使用了,但是在较大大资金时,换手率不能太高,否则交易的冲击成本会上升很多,所以这类资金容量的边际收益其实已经很贴近边际交易成本了。
- 可能在回测的时间段内,机器学习国内的普及还不够广,利用的人还不够多,所以在回测时间段内信息比率比较高。在最近的时间段内,信息比率就接近其他资产的风险回报比率了。
- 在纯多头的情况下,对市场的 beta 风险敞口过大,所以会考虑用股指期货对冲做市场中性策略,赚取 alpha 收益。但是由于股指期货的贴水加大,使得策略整体收益的夏普率接近其他策略,就不会进一步扩大容量了。
怎么看待机器学习在量化中的角色
使用机器学习做策略的最大心理障碍在于很难解释为什么做出这些投资决策。我认为应该更多从统计学的角度来看这个问题。
在整个投资的流程当中,机器学习所扮演的角色更多是“找规律”的工具:我们提供的特征其实是我们对模型的一个引导,希望模型从这些特征中找到规律,同时我们标注的标签是希望模型关注的部分。这其实和我们分析过往的股市表现来学习投资方法是很类似的。
模型有可能会过拟合,但人又何尝不会。当我们根据过往 10 年的基金表现来挑选基金时,其实就是挑选了一个能最好地拟合了过去 10 年的投资策略,这也同样有可能出现过拟合的情况。
把机器学习作为简化统计分析过程的一个工具,还是能有很大帮助的,但它显然不是银弹。
- 例如我们发现在财报发布前后的股票变化规律和平时有一些不同,那我们可以利用机器学习来帮我找到具体不同的地方,而不需要手动分析,节约很多时间。
- 但是如果想要直接把所有信息扔给计算机,显然是不行的,股票市场的样本太少,搜索空间和自由度太高,就没有办法获得有泛化能力的模型。挑选特征和优化模型的过程,其实就是在有方向地减少模型的搜索空间和自由度的过程。
量化优化的思路
对于量化策略的优化,传统的金融工程似乎更多会从因子的角度出发进行挖掘。
- 通过观察市场运行的情况,结合经济学和行为金融学的知识,发掘还没有被模型利用的因子,这里的因子其实是提供了额外的信息。
- 可以通过已有的信息加工出来。例如在量价数据的基础上进行计算得出。之所以手动计算生成因子,是因为机器学习的可学习空间太大,在样本不足的情况下容易过拟合。
- 可以通过场外公开信息的整合。例如龙虎榜的信息,新闻和社交媒体的文本信息,另类数据等。
而从机器学习的角度,可以从数据的利用和产出进行优化:
- 怎样让交易模型的训练和预测模型的训练结合起来,使他们能相辅相成。
- 怎样让模型尽可能地学到我们想让它学的规律,而不是被噪音影响。
- 怎样建模使得模型的训练可以更多模拟人投资的学习过程。
我在这方面准备多看一些 Paper,先学习一下目前在其他时间序列预测方面有没有类似的经验,例如 NLP 中的翻译任务,游戏决策中的强化学习等。
总结
还是很感谢微软提供的这个机会,解答了我若干年前 为什么神经网络在股票市场的数据上无法拟合 的疑问,Qlib 作为量化基础架构方向的项目,也许不如专业私募内的框架完善,但提供了一个很不错的起点,降低了量化的入门门槛,同时也为金融相关的机器学习论文提供了一个可以复现和相互比较的平台。
下一篇博客我再分享一下我为 Qlib 项目贡献的众包数据集,也获得了这次 AI School 的二等奖,希望能对更多人有所帮助。

引用
- Qlib 的 Paper:https://arxiv.org/pdf/2009.11189.pdf
- Qlib 的 Github 仓库:https://github.com/microsoft/qlib
- 我的众包数据集: https://github.com/microsoft/qlib/tree/main/scripts/data_collector/crowd_source